
A brief primer on code formatting
And how I'm implementing formatting early on in Poly

Today, I published an interactive computational essay that explains how code formatting works: https://observablehq.com/@freedmand/pretty-printing.
Formatting is usually not something programming language creators implement early on, or so I would imagine. The more pressing needs might be formalizing the language’s syntax, completing the parser, and getting types implemented (all of which are on my todo list). But I decided to investigate how auto-formatting code works early on and built a basic formatter for the subset of the Poly programming language I’ve implemented so far. I also fell in love with the elegance of the underlying formatting algorithm, which is over 40 years old but still widespread in modern tools, leading me to write up the more in-depth examination linked above.
In this post, I present a more high-level visual explainer of how the time-tested algorithm I discovered works — more in the context of applying it to programming language creation.
What is formatting?
Formatting is the art of beautifying source code. Automated tools called formatters take source code and turn the raw text into something that looks good and is more legible.
In addition to making code look prettier, formatters serve these purposes:
help catch errors — formatted code can reveal mistakes, e.g. mismatched curly braces
unify code style for a programming language, eliminating debates on appropriate syntax
improve developer experience by integrating nicely with code editing applications (IDEs)
result in concise diffs — some formatting styles result in fewer changed lines when minor changes are made to source code
Formatters have been created for almost all established programming languages, but they are no trivial matter. Bob Nystrom, who I cited in my last post, built the official formatter for the Dart programming language and called it in no uncertain terms “The Hardest Program I've Ever Written.”
Creating a formatter is a balancing act of making style rules that are easy to codify and that look pretty. If you are making a formatter on top of an established programming language, like Dart, pretty might mean creating rules that capture how others are coding using the language, i.e. its idiomatic usage. In creating a formatter for Poly early on, I have the luxury of defining my own style rules, since no has used the language in practice.
To refine my desired look, I investigated modern formatters whose output I agreed with, like ReasonML’s formatter refmt and OCaml’s format package. The roots of these tools and others, I found, all traced back to a single paper: Derek C. Oppen’s “Prettyprinting” (1980).
“Prettyprinting”
In the paper, Oppen writes that “the basic idea of how a prettyprinter works is well established in the folklore,” alluding to his method potentially being used before 1980.

— Derek C. Oppen, “Prettyprinting” (1980)
“A Prettier Printer,” by Philip Wadler (2003), is a more recent take on Oppen’s algorithm. The approach is the same but it is adapted for functional languages and is influential in modern tooling. For instance, the Prettier formatting tool (2017) uses the same approach as well to the fanfare of tens of thousands of stars on GitHub — though much of the magic of a good formatter comes from meticulously adding rules for all kinds of edge cases. Still, it is remarkable to me that in a rapidly innovating field, the mainstream technique of beautifying source code is over 40 years old.
How it works
If screens were infinitely wide, formatting would be easy: each statement of source code takes up a single line, extending as long as it needs.
Screens are not infinitely wide, and readers tend to like only having to scan so far horizontally. Source code therefore typically has a default line width. After a certain number of characters are printed, the text will wrap. Formatters can anticipate text extending too far, strategically inserting newlines to prevent long lines.
In the interactive essay linked above, I get into the low-level details of how exactly the formatting algorithm works. Here, I will describe the abstractions of the formatting library I am using (influenced by the Smart Print library), and how they simplify the task of formatting a programming language.
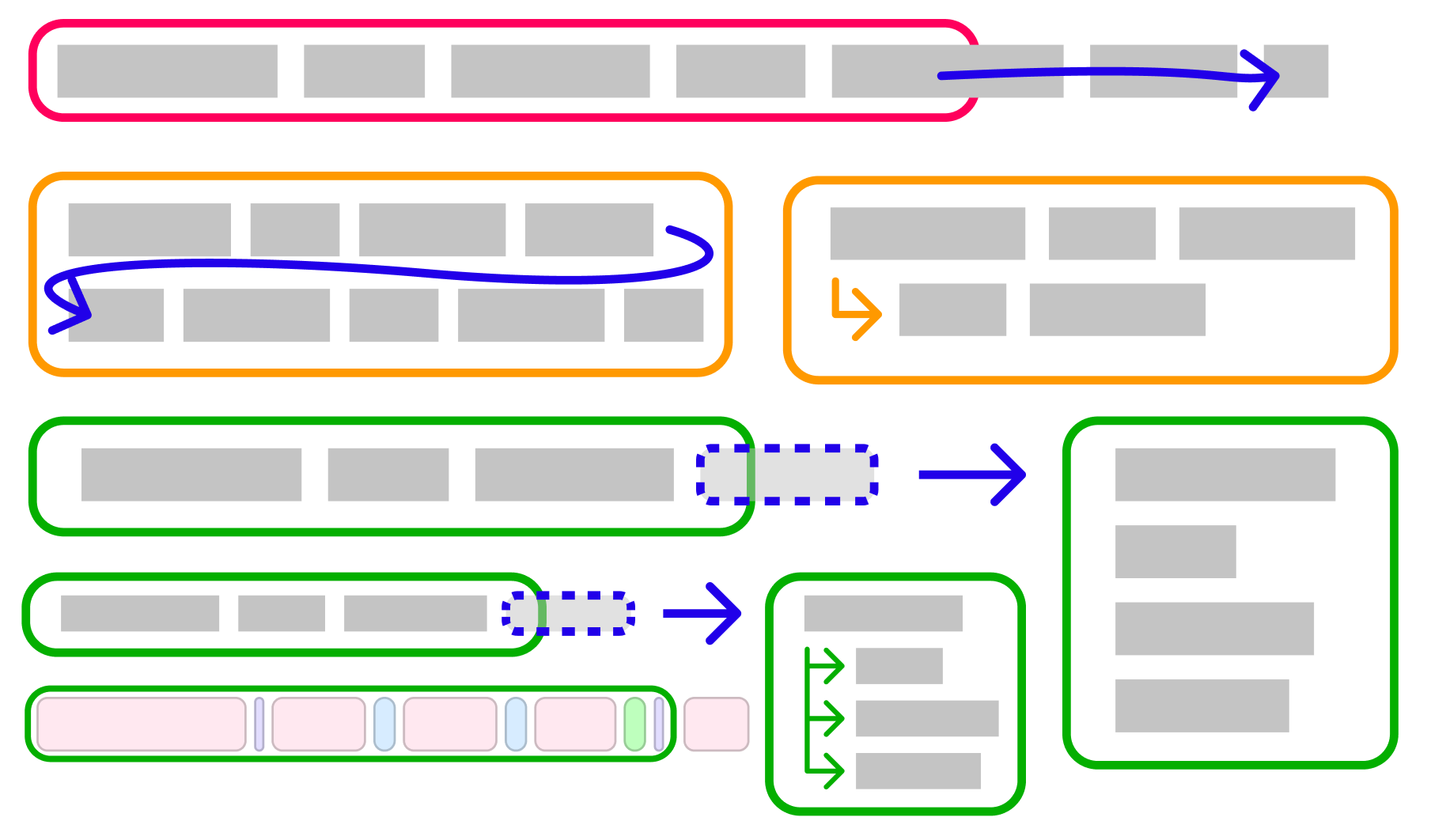
Boxes
Text can wrap in different ways. Below I present three types of boxes, which can wrap in different ways. Each box contains a list of elements, where each element can be text, whitespace, or other boxes.
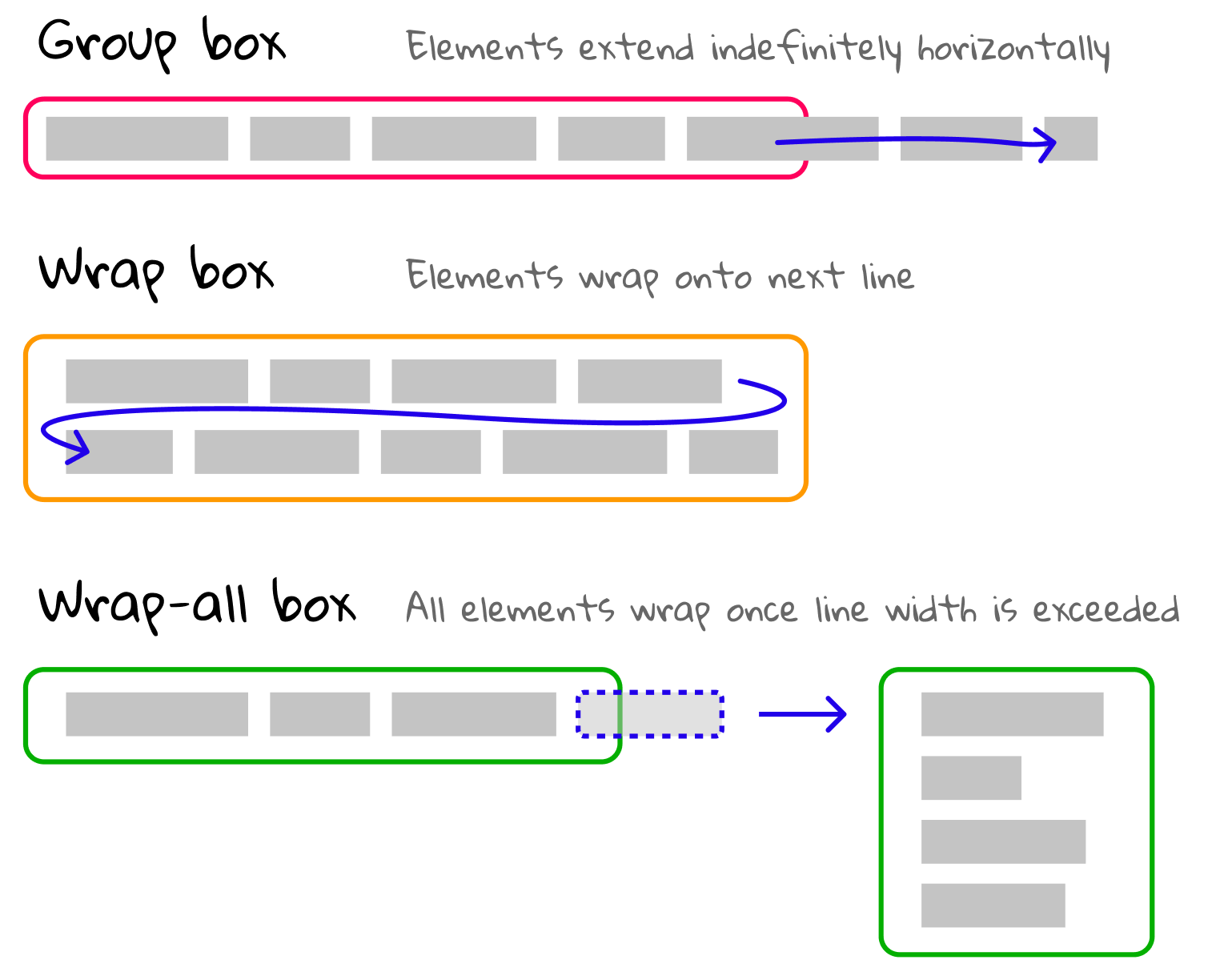
A group box prevents elements from wrapping. If there are words or tokens you want to ensure are on the same line no matter what, put them in a group box.
A wrap box resembles more or less how text is formatted in word processors and typewriters. Once an element exceeds the preset line width, that element moves onto the next line, which continues horizontally.
A wrap-all box is a wrap box with special behavior. Once the line width is exceeded, the element that extended too far gets a new line — as does every other element. This behavior is common in programming, where some terms are grouped on the same line if possible, or all on separate lines if not.
Nesting
When text extends too far on a line and gets wrapped onto additional lines, it can be useful to indent those lines to distinguish them. This behavior is called nesting and can be applied to wrap and wrap-all boxes. Nesting is popular in programming, e.g. when writing curly brace blocks or splitting long statements.

Whitespace
Lastly, whitespace is used to determine where lines can be split. There are several kinds of whitespace that I am using:
newline: the algorithm splits the line at this point (no matter what) and puts the rest of the content on a new line.
space: the algorithm adds a space at this point, unless the text extends too far horizontally. In a wrap box, a newline will be added instead of a space to put the over-extended text on a new line. In a wrap-all box, all whitespace in the box is changed into a newline as well.
blank: the algorithm does not do anything here unless the text extends too far in a wrap-all box, in which case a newline is inserted at this point. We’ll see below how this is useful.
only show if wrapped: Similar to blank, the algorithm does not do anything here unless the text extends too far in a wrap-all box, in which case some specified text is rendered. This lets us specify trailing commas in arrays that only show when split on multiple lines.
With these abstractions, code can be formatted fairly expressively. The formatting algorithm looks ahead only a line at a time, selecting the best layout that puts as much text as possible on the same line, without exceeding the line width if possible.
Examples
Here’s an example of how one might layout and format an array declaration:

In this example, the majority of the text is in a wrap-all box with nesting, meaning once the line width is exceeded all the elements wrap with indentation. The end of statement — ]; — is outside of the wrap box, since this text should be on its own un-indented line at the end. All whitespace — spaces and blanks — is faithfully converted to newlines when wrapping. We also specify a trailing comma at the end of the array list that only displays when the array is split onto multiple lines.
Special considerations
One downside of this algorithm is that it’s possible for text to exceed the line width. This might occur if you have an extremely long variable name, for instance. Written prose typically accommodates such formatting dilemmas with hyphens that break a word; in source code, it’s permissible to let these exceptional cases slide every now and then. It’s not the end of the world if the line is too long, but we try to avoid it if possible.
Auto-formatting source code
The general process of auto-formatting source code is 1) parse the code, 2) feed the abstract syntax tree (AST) describing the code into a layout algorithm, which outputs boxes that can then be 3) formatted and displayed using the formatting algorithm. It’s akin to breaking up a program’s text into formatting boxes and then reconstituting the text from those boxes. Accounting for non-essential source code text like comments requires storing this non-essential code in the parse tree.
I’ve found that creating the actual layout algorithm to turn source code into formatting boxes is the hardest part. There are many non-intuitive style idioms people use while coding that require carefully specifying special cases.
My strategy for defining Poly’s formatting style thus far has been to replicate style idioms I like from other programming languages and invent some of my own. I am focusing on a mix of rules that are easy to codify while still producing subjectively pretty output.
My test suite for formatting has more unit tests than any other module currently. In addition to making sure all the edge cases I’ve discovered format correctly, the tests serve to validate my parsing approach and ensure the source text can be accurately reconstructed. There are some monstrous test cases I’ve implemented which ensure the passed in source text reconstructs to itself, including this one:
let x =
2342352
* (
234
+ 2348989
- 143
* (
2341
- 34
* (
3423
- 1349
+ 23423409
+ (23 - 3453253 - 234324 + 23 + 2354235 + 234 + 24)
)
)
);In this example, I am following a formatting style influenced by ReasonML’s refmt. The wrapping behavior for expressions prioritizes starting new lines with operators (plus, minus, times, etc.) where possible instead of literals like numbers. This behavior was tricky to implement with the constraints of the box approach above, but ultimately I got it working in the layout algorithm by placing the operator and second term of binary operations in a group box together.
Another edge case that required finesse: handling negative terms. Technically code like “2 - -2” is allowed (2 minus negative 2), but it looks better if the negative 2 is enclosed in parentheses (“2 - (-2)”). This requires rewriting the parse tree to enclose the negative number literal in a grouping node. The following test case validates complicated negative expressions are formatted correctly:
let x = [
124135,
(-345) - (-3523),
134 + ((-352) - (-9)),
- ((-234) - 352),
34 + 234 + (-134915),
];I am still early in the process of specifying my language’s grammar and have already found myself implementing many formatting edge cases. For instance, having a declaration statement that specifies an array is specially handled compared to a declaration for another kind of expression.
As tedious as the process is specifying all the loose syntactic ends, there is something undeniably satisfying about seeing your code auto-format into a more structured and beautiful form.
Closing notes
I’ve started implementing an auto-formatting tool for the Poly programming language, early in the language’s development. I expect this tool will solidify idiomatic style and prevent future debate on language style, improve the developer experience early on, and save me from many headaches had I tried to build a formatter after the language was more-or-less done.
To learn more about the underlying formatting algorithm, check out the interactive essay I wrote and read “A Prettier Printer” by Philip Wadler (2003) and “Prettyprinting” by Derek Oppen (1980).